New Publication
Predicting individuals' car accident risk by trajectory, driving events, and geographical context
Computers, Environment and Urban Systems
https://doi.org/
Livio Brühwiler, ChengFu, Haosheng Huang, Leonardo Longhi, RobertWeibel
Abstract
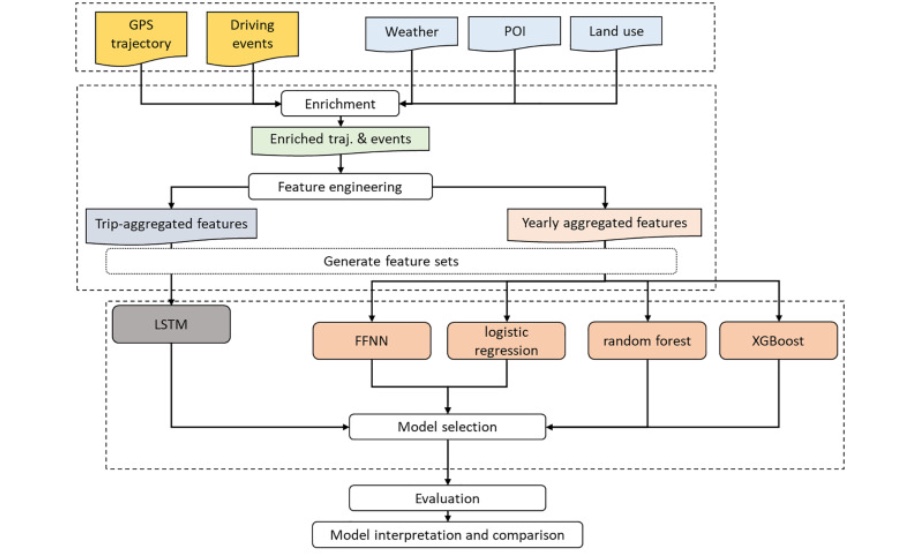
With the prevalence of GPS tracking technologiees, car insurance companies have started to adopt usage-based insurance policies, which adapt insurance premiums according to the customers' driving behavior. Although many risk models for assessing an individual driver's accident risk based on the history of driving trajectories, driving events, and exposure records exist, these models do not take the geographical context of the driven trajectories and driving events into account. This study explores the influence of enriching the existing purely driving-behavior-based feature set by multiple geographical context features for the task of differentiating between accident and accident-free drivers. Prediction performances of five machine learning classifiers—logistic regression, random forest, XGBoost, feed-forward neural networks (FFNN), and long short-term memory (LSTM) networks—were evaluated on the usage records of over 8000 vehicles in one year from Italy. The results show that the inclusion of geographical information such as weather, points of interest (POIs), and land use can increase the relative predictive performance in terms of AUC by up to 8%, among which land use is the most informative. For the data of this study, XGBoost generally yielded the best performance and made most use out of the geographical information, while logistic regression is only slightly outperformed by more complex models if the proposed geographical information is not available. LSTM did not outperform the other methods, possibly due to the small volume of training data available. The results outline the potential of including the geographical context in usage-based car insurance risk modeling to improve the accuracy, leading to fairer usage-based insurance policies.
https://doi.org/10.1016/j.compenvurbsys.2022.101760